Sharding a relational database
Neil’s notes:
- Queues can’t escape overload, the database is the bottleneck
- Spread the write load horizontally across multiple machines (sharding)
- Sharding requires significant day 1 work
- Re-sharding cost is very real
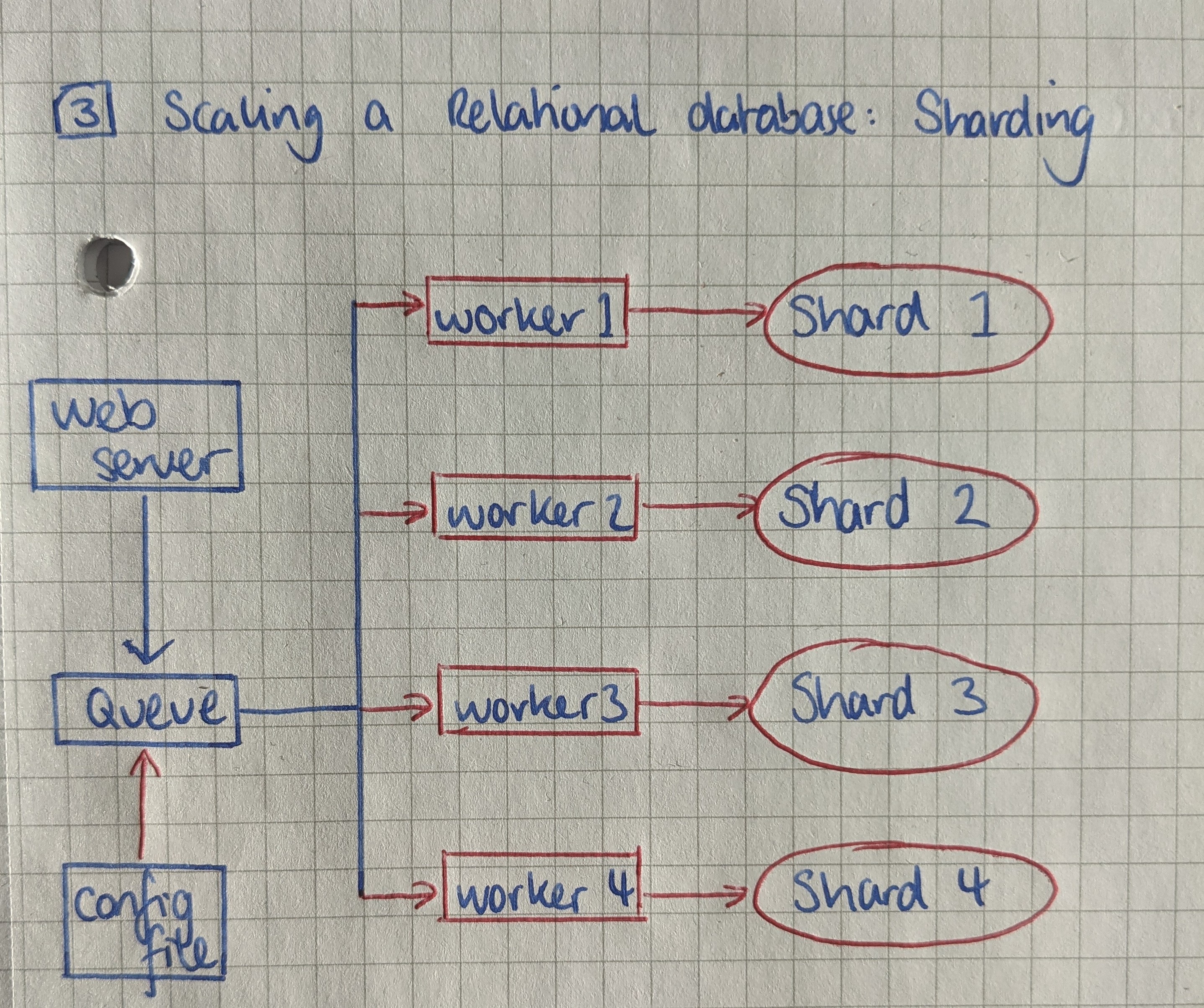
Your application goes viral. Your worker can’t keep up with the writes so you add more workers and parallelise the updates. This works for a short time but you realise the bottleneck is in the database.
A Google search on scaling write-heavy brings up Sharding or horizontal partitioning. To spread the write load by partitioning the table across multiple servers using a shard key.
How to shard:
- Choose a hash function
- Shard_id = hash(key) mod n_shards
You write a script to map all the rows of your table to you hash function and split the table into 4 shards. It takes a while to run and you don’t want new pageview increments to unbalance your uniform partition. You decide turn off the worker till partition completion caching the interim pageview increments.
Your application now needs to know how to find the shard for each key so you wrap a library around your database handling code that reads the number of shards from a new configuration file you created.
You also write additional logic to query the top 100 URLs from each shard and merge them to return a global top 100 URLs.