Queueing a relational database
Neil’s notes:
- Hitting the database directly is bad
- Adding a queue helps
- Batching updates helps
Suppose you decide to build a simple web analytics application.
The application you have in mind tracks the number of pageviews for any URL a customer wishes to track. Additionally, the application should be able to report the top 100 URLs by number of pageviews.
You start with the following data schema:

You build the back end to consist of a Relational Database Management System (say MySQL), a table with the above schema and a web server. Each time a web page tracked by your application is loaded, the web page pings your web server with the pageview, and your web server increments the corresponding row in the database.
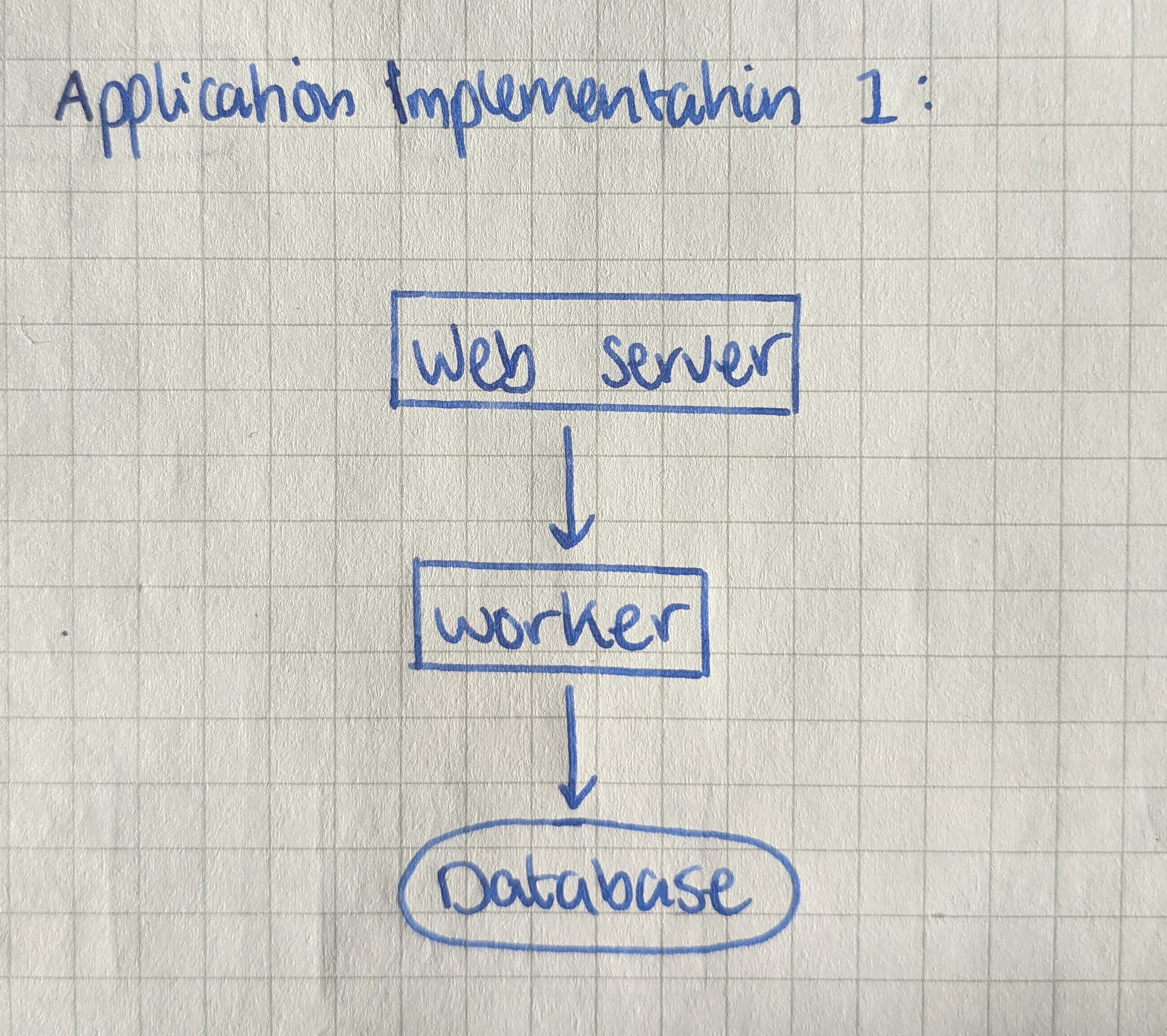
The web application is a success, and traffic is growing like wildfire. You start getting lots of emails from your monitoring systems all with the same error:
“Timeout error on inserting to the database”
Your logs tell you that write requests are timing out because the database cannot keep up with the load. Your system is losing valuable information and you need to act quickly.
You realise that it is inefficient to perform a single increment per request. You draw up and implement a queuing system between the web server and the database so whenever a pageview is received, that event is added to the queue. You also create a worker that reads 100 events at a time off the queue and batches them into a single update request to your database.
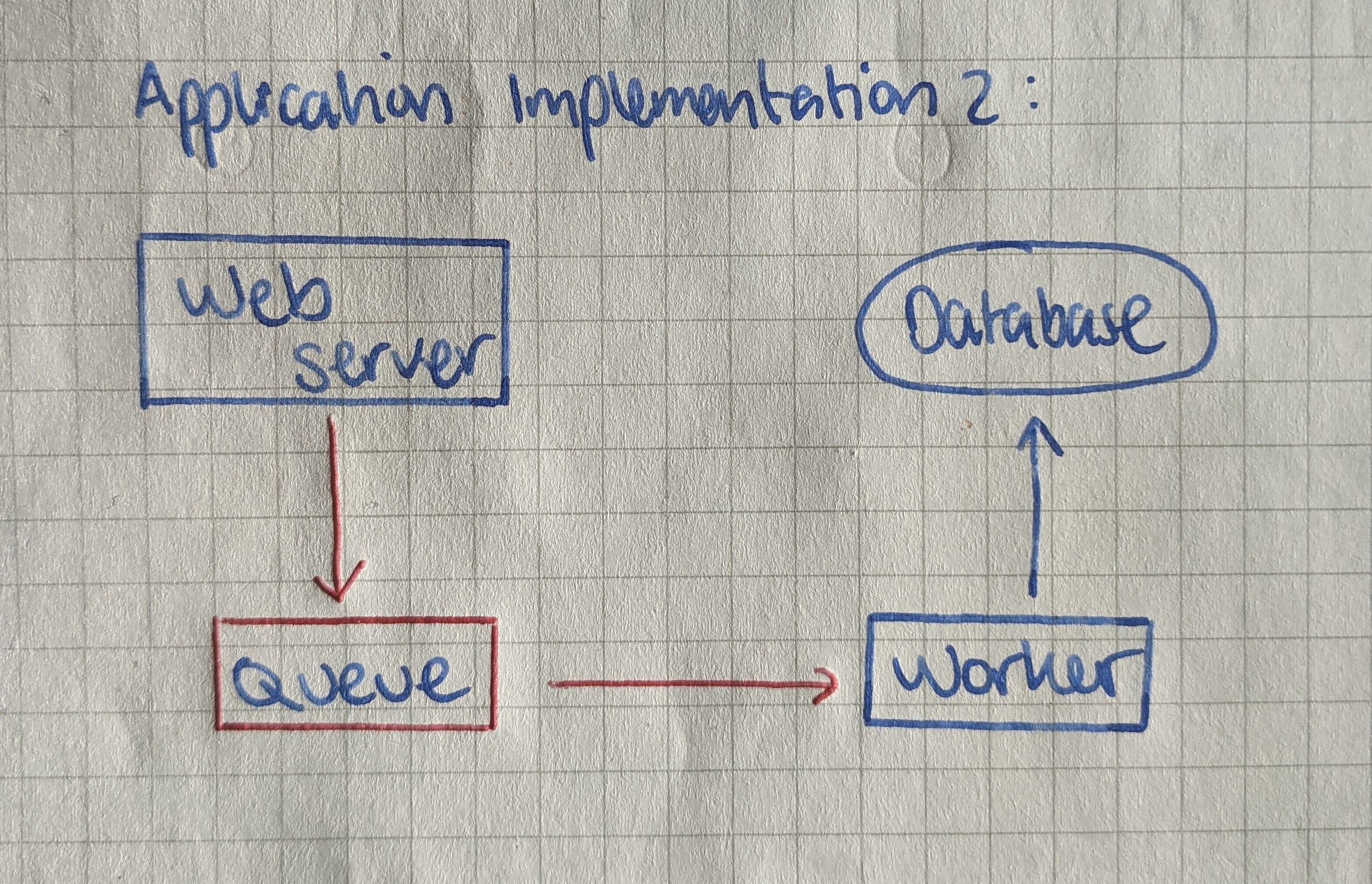
It works well and the web server no longer pings the database directly and you no longer receive timeout notifications!