D1.1 - info, data, queries, views
This is the first dissection piece on www.whatprinted.com. It will span at least 3 blog entries and will primarily poke holes in the robustness property of this data system. I’ve called it D1.1 for those who like an organised homepage.
The service has been running for free for 2+ months now. There have been no bugs yet but there have also been no more features shipped. In the last article, you saw the data architecture for this service.
At the core of this architecture is the ‘master dataset’. This stands as the source of truth for the system. Fancy phrase but what does that mean? Well, if I was to lose every single part of the system after the master dataset, I could still reconstruct the service easily with no loss of data.
In the past, overloaded machines, failing disks and power outages could all destroy systems but today most of those risks can be offloaded to cloud vendors (at a price). Human error remains which is an inevitable eventuality. Still, the master dataset should be protected from corruption at all costs.
There are two components to the master dataset: the data model and the physical storage. I care about the data model. If all queries are functions of data, the data model is the structure organising data to be consumed by your function.
We’ve talked about data, information and queries before (data vs info). Let’s have a look how that applies in an example related to our service.
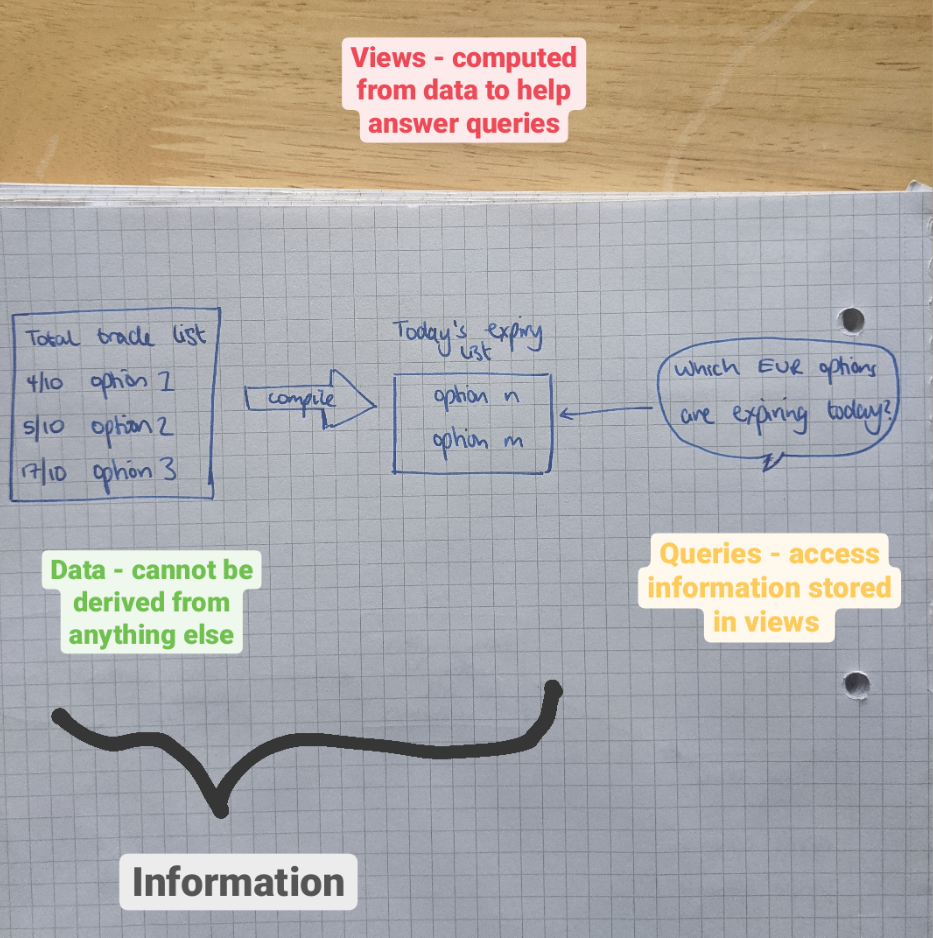
If this makes no sense to you then check out the previous blog (dissection).
Why is this important? Firstly, it helps conceptualise an end-to-end data pipeline. Secondly, and crucially, provides the basis we need to discuss 3 core concepts to developing data models that do most of the fault-tolerance/robustness heavy lifting. In other words, ‘are these results accurate?’ will be a whole lot quicker, easier, less stressful to answer. And let’s face it, less stress = more happy.