Shy code, loud systems
High concentration, low upside
Have you ever tried to use a heavy excel spreadsheet, with multiple tabs and thousands of rows and columns. If you are lucky enough to spot an error in an important cell, you trace its dependents and get pointed to 4 more cells. Each of those 4 cells, are dependent on 3 more cells, and so on. Before you know it, two hours have passed and you’ve performed at least 4 forward and backward traces in an attempt to correct the original error. The cost of this process is not only time and opportunity cost, but something equally precious and in limited supply, concentration.
High-concentration-low-upside tasks are incredibly costly and yet incredibly common across industries. How do you spot these tasks? If you feel like you need a mental break after completing a task that has to be done at least once a week and is not mentioned in your appraisal or you don’t get a bonus for doing it well.
I’m not even going to discuss those who don’t see this as a problem. Those who do could address it by reducing the amount of human concentration required to complete. Ideally to 0 concentration (autonomous system), but in the near term to ‘low’ or ‘very low’. And the way to achieve this is to write software.
But I thought programming was magic?
The thing about software is that errors don’t disappear into a black hat. They still exist. It’s just that the software creator now has the power to make the experience of encountering errors as pleasant or as unpleasant as they like. Here’s how to avoid the latter: 1) make sure the software creator understands the current pain, 2) see 1).
People who program their way out of the lame tasks they face will always understand the pain. And if it is important enough to them, they learn whatever programming principles needed to implement something decent. As a side note, I started doing consulting work this year, so for the first time I got a taste of learning the pain and then programming to solve it; it’s way harder that just solving your own problems.
Reversibility & coupling
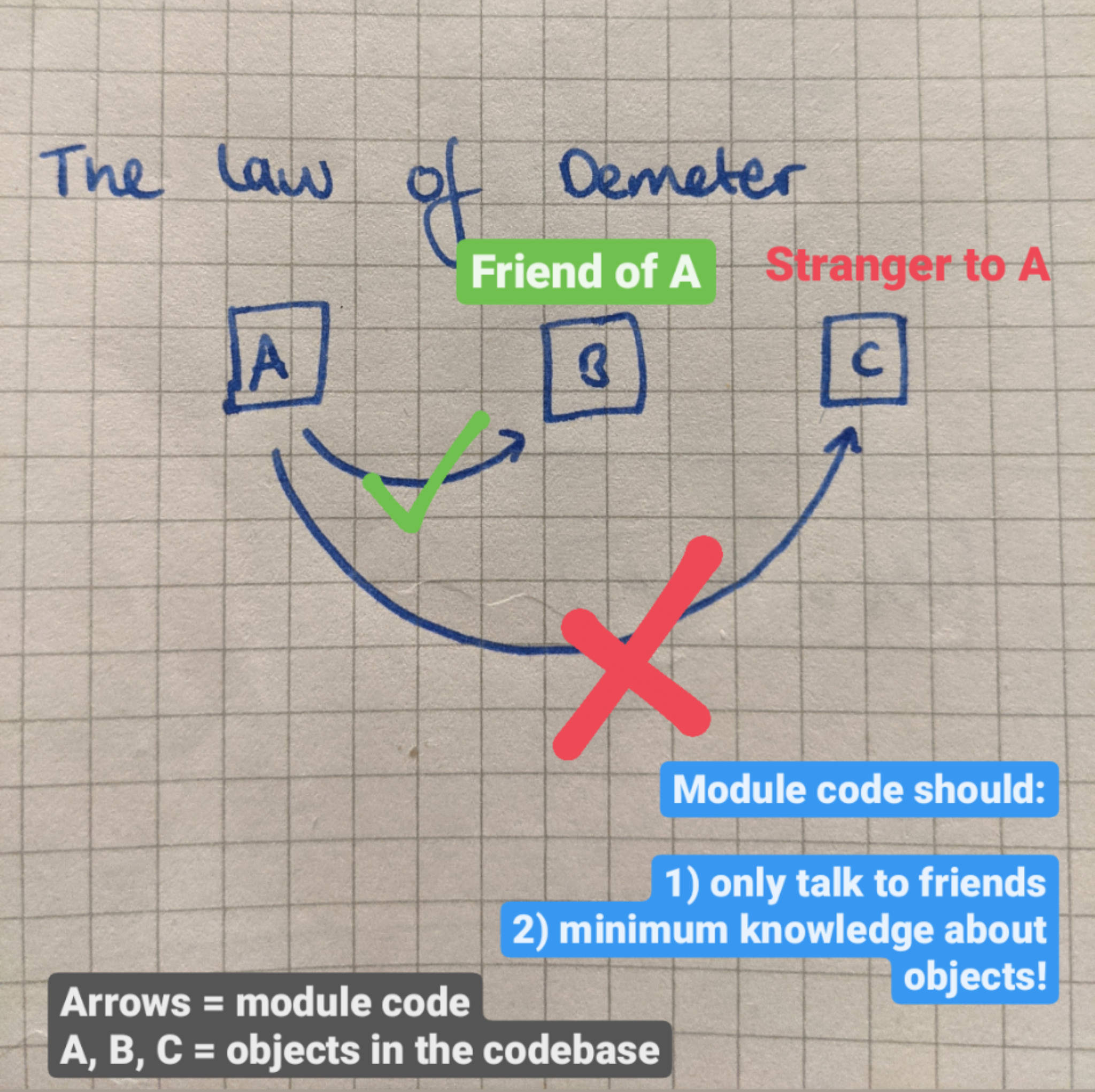
Even if the task is well understood, software can still introduce more problems. The Pragmatic Programmer, Hunt & Thomas have a section about reversibility and coupling of modules within systems. It advises how to make the experience of encountering errors when creating software pleasant. I particularly like the section on the Law of Demeter, or the principle of least knowledge. It states two things:
1) Module code should only talk to friends
2) Module code should have minimum necessary knowledge about objects in the codebase
Shy code, loud systems
If abided by, the law helps ensures errors can be traced to their source easily and quickly through reducing the coupling between each unit in the software’s code base. Not only that but the code base in general can be more quickly understood since modules are only related through a light interface without knowledge of module internals aka shy code.
In terms of our initial example, there may be more steps to trace but each unit traces back to a single source that can be tested easily. If implemented correctly, changes to one module should have minimal ripple effect into another.
If it’s loud systems you want, then it’s shy code you gotta write.